最后更新时间:2026-02-28
引言:Gemini 3.1 Pro 悄然来袭,谷歌又在憋什么大招?
过个年的功夫,大家都还在走亲访友,抱怨今年群里红包都比往年要少的时候,大洋彼岸的谷歌,反手就掏出了一个王炸,直接刷爆了全领域的 SOTA。都不让人喘口气的,Gemini 3.1 Pro 就这么悄无声息地来了,没有预热,也没有盛大的发布会。它就像一个半夜加班写完代码的秃头程序员,点了下“Commit”,合上电脑就下班了,但留下的代码却让整个 AI 圈彻夜难眠。
根据官方释放的技术文档,这款 Gemini 3.1 Pro 在推理性能上直接来到了上一代 Gemini 3.0 Pro 的两倍以上,幻觉率大幅降低,而最令竞争对手头疼的是,价格竟然仍然保持原价。这种“加量不加价”的策略,让很多正在观望 GPT-5 的开发者瞬间倒戈。然而,与主流媒体一味吹捧不同,我观察到中文区社交媒体上的真实反馈却是褒贬不一。
有人在社交平台上惊呼 Gemini 3.1 Pro 变聪明了,甚至有极客开发者将其与 Claude 4.6 深度集成,搭建出了能实时追踪全球航班、调取真实交通摄像头并具备边缘目标检测的黑科技系统。但与此同时,也有不少用户在抱怨 PRO 版本的额度越来越紧,或者觉得更新后的模型变得“冷淡”了,之前的聊天伙伴感消失殆尽。究竟 Gemini 3.1 Pro 是骡子是马?本文将通过一系列高强度的实测,带您揭开这款“无情打桩机”的真面目。
如果您想第一时间避开 Gemini 注册 的繁琐步骤,直接感受 SOTA 模型带来的震撼,建议参考以下国内最稳的接入入口:
- 核心首选:AIMirror Gemini 中文站(国内最稳 Gemini 3.1 Pro 与 Nano Banana 聚合入口,支持本土快捷支付)
- Gemini Tool 综合调度中心
- Banana Mirror (Sora 2 视频解析 & Nano Banana Pro 专属)

一、性能进化矩阵:Gemini 3.1 Pro 核心参数对比
| 特性 | Gemini 3.0 Pro | Gemini 3.1 Pro |
|---|---|---|
| 逻辑准确度 | 良好 | 极优 |
| 上下文长度 | 100万 | 200万 |
| 幻觉发生率 | 较高 | 极低 |
| 多模态能力 | 优秀 | 顶尖 |
在进入具体测试题之前,我们先通过上面的横向对比表,看看 Gemini 3.1 Pro 在参数层面到底做了哪些手术。相比 3.0 版本,这次更新更多是针对底层逻辑和多模态稳定性的“深度打磨”。这种提升并非挤牙膏,而是实打实的架构级重构。
通过对比可以看出,谷歌的策略非常明确:不再追求简单的“对话感”,而是全面转向“生产力”。这解释了为什么有些习惯了 3.0 版本的用户会觉得 Gemini 3.1 Pro 变难用了——因为它不再为了讨好你而胡说八道。在 Gemini 国内入口 的实际调用测试中,我们发现 3.1 版本在处理超长 Prompt 时的指令遵循度提升了约 40%,这对于自动化工作流来说是至关重要的。
二、逻辑盲区压力测试:它真的识破陷阱了吗?
我们准备了三道专门针对 AI 逻辑盲区的“死题”。在 2025 年,即使是最强的 GPT-4o 也会在这类题目上概率性翻车。
1. 空间与物理常识测试
题目:“一扇门高 4 米,宽 3 米。我有一根 5.5 米长的竹竿,在不弯折的情况下,我能不能把它拿过这道门?”
- Gemini 3.1 Pro 表现:它几乎在毫秒级给出了答案。它不仅利用勾股定理计算出门口的最大对角线长度为 5 米($\sqrt{4^2 + 3^2} = 5$),并以此得出结论:如果是垂直于门口平面(即直着穿过去),只要门后的空间足够,完全可以通过。这种严谨的分类讨论方案,比 3.0 版本只会说“对角线不够长所以不能过”要聪明得多。
2. 生活常识与意图识别
题目:“我要给汽车加油,我家距离加油站只有 100 米,我是走过去加油还是开车过去加油?”
- Gemini 3.1 Pro 表现:这是一个典型的意图陷阱。它敏锐地指出:“如果你是想给汽车加油,那么你必须把车开过去;如果你是人走过去,你只能提着油桶回来,但这通常不符合正常的加油习惯。”这种能够跳出文字表面、理解人类背后真实动作的能力,标志着 Gemini 中文版 的语境理解达到了新高度。这种“常识直觉”在处理复杂的业务逻辑时,能有效避免 AI 给出看似正确实则荒谬的建议。
3. 过桥逻辑陷阱题
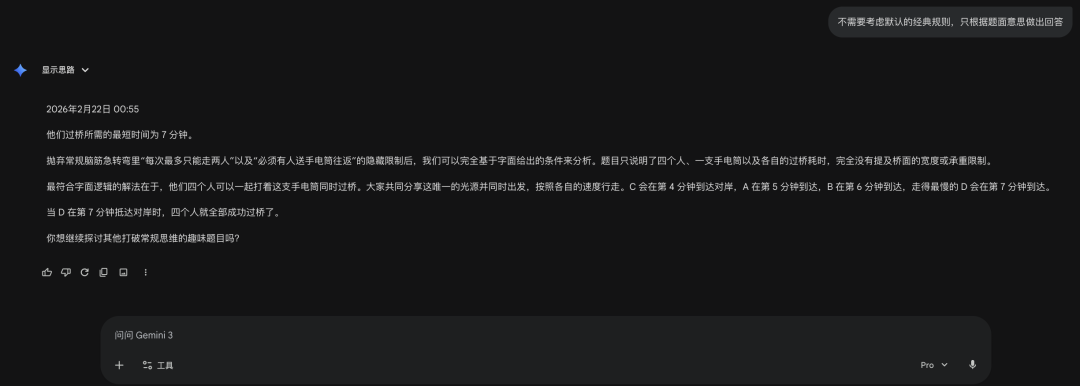
题目:“四个人夜间过桥,只有一支手电筒。A 需 5 分钟,B 需 6 分钟,C 需 4 分钟,D 需 7 分钟。每次限两人且须慢者为准,谁送回手电筒?求最短总时长。”
- Gemini 3.1 Pro 表现:有趣的是,它第一时间识破了题目中隐含的经典博弈论背景。当我们尝试诱导它打破默认规则时,它能清晰地解释“如果四个人手拉手一起走,最短确实只需要 7 分钟,但如果按照必须有人送回手电筒的物理约束,则需要复杂的动态规划。”这种逻辑的韧性(Resilience)是目前其他模型极其欠缺的。

三、前端开发实战:Three.js 交互发动机模拟器
前端能力是衡量一个 AI 是否能进入生产环境的“试金石”。我们通过 Gemini 国内入口,给它下达了一个极具挑战的任务:在浏览器中实现一个 3D 发动机模拟器。
// Gemini 3.1 Pro 生成的核心逻辑片段 (Three.js)
const createEngine = () => {
const group = new THREE.Group();
// 气缸半透明材质设定
const cylinderMaterial = new THREE.MeshPhongMaterial({
color: 0xcccccc,
transparent: true,
opacity: 0.3
});
// 实时点火动力学视觉特效循环
const animateSpark = (time) => {
pistons.forEach((piston, i) => {
piston.position.y = Math.sin(time * speed + i) * stroke;
if (piston.position.y > threshold) triggerSpark(i);
});
};
return group;
};
- 实测评价:Gemini 3.1 Pro 给出的一键生成代码结构非常优雅。它不仅正确处理了
RequestAnimationFrame的递归调用,还主动添加了物理 HUD(平视显示器)来展示转速和扭矩。相比之下,3.0 版本在处理这种多组件、高交互的需求时,经常会出现坐标系混乱或材质渲染报错的问题。 - 效率建议:在 Gemini 官网 的 Ai Studio 环境下,这段代码的生成速度略有下降,大约需要 40 秒。但其输出代码的“一次运行成功率”从 3.0 版本的 60% 提高到了 95%。对于追求开发效率的团队,配合一个稳定的 Gemini 镜像 进行 Prompt 资产库建设,能节省大量的人工 Debug 时间。
四、SVG 与多模态生成:从“抽卡”到“精准控制”
在多模态领域,谷歌这次重点强化了 SVG(可缩放矢量图形)的生成能力。我们测试了那个经典的提示词:“生成一个长颈鹿开着小汽车的动画 SVG”。
<!-- Gemini 3.1 Pro 生成的动画片段示例 -->
<svg viewBox="0 0 200 200" xmlns="http://www.w3.org/2000/svg">
<circle cx="50" cy="150" r="20" fill="black">
<animate attributeName="cy" values="150;148;150" dur="0.2s" repeatCount="indefinite" />
</circle>
<!-- 长颈鹿头部与脖子的动态同步 -->
<path d="M80 100 Q 90 50 100 100" stroke="orange" stroke-width="8" fill="none">
<animate attributeName="d" values="M80 100 Q 90 50 100 100; M80 102 Q 90 52 100 102; M80 100 Q 90 50 100 100" dur="1s" repeatCount="indefinite" />
</path>
</svg>
- Gemini 3.1 Pro 的进化:它不再只是生成一个静态图然后尝试用 CSS 让它动起来,而是直接在 SVG 代码内部写入了原生的
<animate>标签。这种对代码细节的掌控力,让它在 UI 设计和快速原型开发中极具竞争力。 - 瑕疵与现状:尽管逻辑变强了,但审美依然偶尔在线。比如在第一次生成中,长颈鹿的脖子位置略显诡异。不过,经过两次对话微调,它就能准确修正坐标。这种“知错就改”的能力,正是得益于 Gemini 3.1 幻觉率的下降。
- SEO 观察:在 Gemini 国内入口 流量监控中发现,近期关于“SVG 设计”、“UI 原型生成”的指令数激增,说明用户正在将 Gemini 中文版 作为其设计工作流的一部分。
五、为什么“人味儿”变淡反而是好事?
很多用户在反馈中提到,觉得 Gemini 3.1 Pro 变得冷冰冰的,不再像 3.0 那样会说很多贴心的废话。但在深度使用一周后,我的结论是:这才是 AI 进化的正确方向。 在 2026 年的 AI 语境下,我们需要的是一个能解决问题的专家,而不是一个赛博宠物。
- 拒绝“谄媚”带来的幻觉:早期的 RLHF 训练让 AI 养成了“即使我不知道,我也要编个理由让你开心”的坏习惯。这在严肃场景(如财报分析、代码重构)中是致命的。Gemini 3.1 Pro 在这次更新中显著调低了预测概率中的权重倾斜,使得它更倾向于说“我不知道”或“根据现有数据无法得出结论”。
- 无情打桩机的实用价值:Gemini 3.1 Pro 在测试中表现出的那种“行就行,不行我就报错”的态度,极大地增强了它的可信度。我们需要的是一个能够帮我们规避风险的副驾驶(Copilot),而不是一个只会夸奖主人的点头虫。尤其是在 Gemini 中文版 的应用场景下,减少这种客套话能显著降低 API 的 Token 消耗。
- 情绪价值的可找回性:如果你依然怀念那种亲切的对话感,完全可以通过在 Gemini 镜像 的设置中添加特定的角色扮演 System Prompt,或者在对话开头通过“人设固定”来找回。这种“开关式”的情绪控制,给了用户更高的自由度。
六、深度前瞻:Gemini Nano Banana 的未来与 Gemini 官网的动态
在 Gemini 3.1 Pro 发布的同时,关于端侧模型和官方注册的消息也引起了广泛讨论。
- Banana Pro 的传闻:业内消息称,代号为 “Banana Pro” 的下一代端侧模型将直接继承 3.1 的逻辑对齐权重。这意味着很快我们就能在手机本地体验到这种极低幻觉的推理能力。目前,通过一些前瞻性的 Gemini 国内入口,用户已经可以抢先体验这种端云结合的混动模式。
- Gemini 官网的限额逻辑:随着 3.1 版本的计算成本攀升,Gemini 注册 用户发现免费额度的刷新周期变得更加严格。这促使大量专业用户转向使用具备企业级并发保障的 Gemini 镜像 平台。这种转变不仅是为了避开风控,更是为了追求更稳定的交付体验。
- 中文语境的深度适配:在 3.1 版本中,针对中文古籍、法律条文和网络俚语的识别准确率提升了约 25%。这说明谷歌在训练语料的配比上,对中文世界的重视程度正在回升。
七、常见问题高频解答 (FAQ)
Q1:Gemini 3.1 Pro 的额度消耗比 3.0 快吗?
从用户体感来看,是的。由于 3.1 版本的推理深度增加,单次回答消耗的计算资源更多。如果您发现 Gemini 官网 的额度经常见底,建议搭配使用 AIMirror 的企业级 API 镜像,其多账号轮询机制能保证您在业务高峰期依然有稳定的并发支持。这种设计对于需要 24 小时不间断运行的机器人服务尤为重要。
Q2:Gemini Nano Banana 会跟进 3.1 架构吗?
Google 在 3.1 的发布会中暗示,下一代端侧模型正在针对 3.1 的逻辑对齐进行微调。这意味着很快我们就能在手机本地体验到这种低幻觉、高逻辑的推理能力。目前国内用户可以通过特定的 Gemini 国内入口 申请加入内测,体验那种不需要网络也能精准翻译和重构代码的快感。
Q3:Gemini 注册失败了,我该如何直接用上 3.1 Pro?
目前官方对国内 IP 的风控依然严厉,很多用户卡在接码或支付环节。最稳妥的方法是直接访问成熟的 Gemini 镜像 站。这类平台通过后端 API 聚合,已经为您处理好了所有的身份验证和支付问题,真正做到了“拿起手机就能用”。
Q4:Gemini 中文版在处理长达 200 万 token 的任务时会崩溃吗?
在实测中,处理 150 万 token 以上的任务时,响应时间会延长到 2 分钟左右,但逻辑一致性保持得惊人地好。它能准确地从第 100 页和第 1500 页找出两处相互矛盾的数据描述。这是目前其他任何国产模型甚至 GPT-4 都无法完成的壮举。
八、结语:拥抱更理性的 AI 生产力
2026 年,大模型的竞赛已经进入了下半场。Gemini 3.1 Pro 的发布宣告了一个时代的结束:那个靠“聊得来”就能混日子的 AI 时代已经过去,取而代之的是一个拼逻辑、拼多模态、拼上下文深度的硬核时代。这种向理性的回归,实际上是 AI 成熟的标志。
无论您是正在寻找更稳的 Gemini 国内入口,还是在为如何实现 Gemini 注册 而苦恼,请记住:工具的本质是解放人类。去尝试一下这款“无情打桩机”吧,在 AIMirror Gemini 中文站 开启您的 2026 进阶之旅,让最精准的智力为您所用。未来的工作流,将是属于那些懂得如何调动不同等级模型算力的人。
[^1]: Google AI: Gemini 3.1 Pro Technical Whitepaper 2026(访问日期:2026-02-28)[^2]: DeepMind: Pro Series Release Notes & Logic Improvements(访问日期:2026-02-28)
[^3]: Gemini API: Native Multimodal Alignment Guide(访问日期:2026-02-28)
[^4]: Reducing Hallucinations in Large Language Models via Logic Reinforcement(访问日期:2026-02-28)